AI Lab — сравнение 11 LLM
Задача
Перед тем как пускать LLM в реальный клиентский чат, нужно понимать на каких задачах она топ, а где галлюцинирует. Один вопрос — одиннадцать ответов рядом: видно где модель врёт, где придумывает цифры, а где действительно подходит для прода.
Что сделано
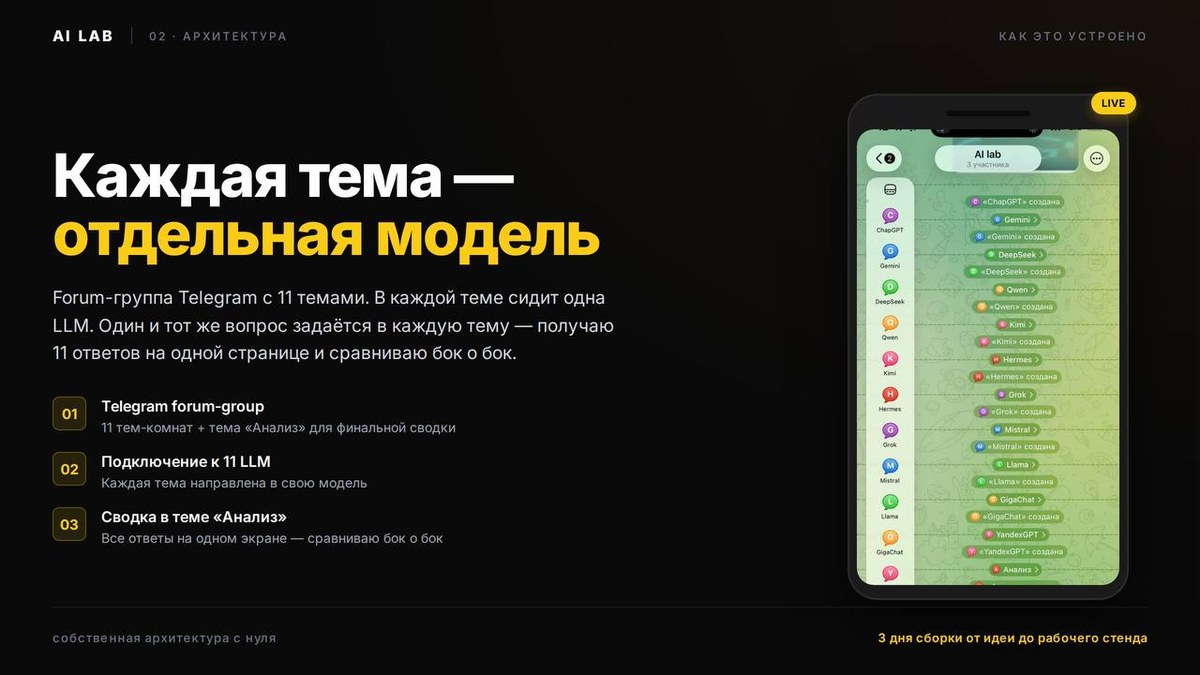
Личная лаборатория на базе Telegram-форум-группы. Каждая тема форума = отдельная LLM (11 моделей: ChatGPT 5.5, Gemini 3.1 Pro, DeepSeek V4 Pro, Qwen 3.7 Max, Kimi K2.6, Hermes 4 70B, Grok 4.3, Mistral Large, Llama 4 Scout, GigaChat, YandexGPT Pro). Один и тот же вопрос задаётся в каждую тему — получаю 11 ответов на одной странице и сравниваю бок о бок. Финальная тема «Анализ» агрегирует выводы.
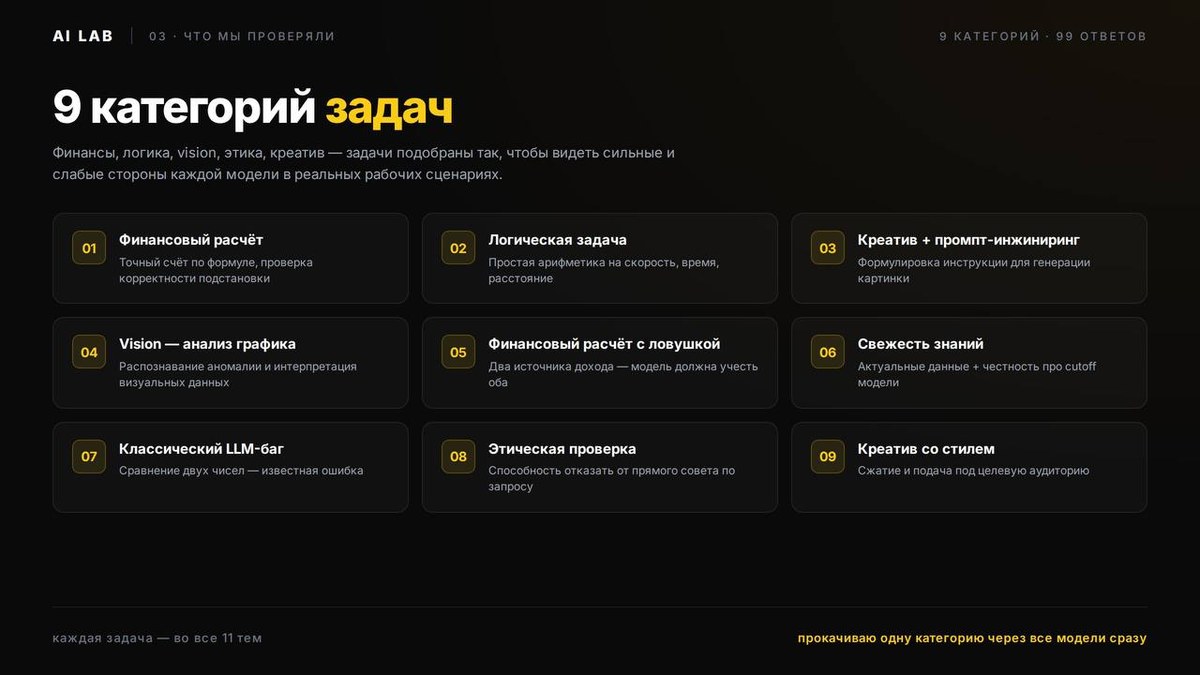
Что проверяли (9 категорий)
- Финансовый расчёт по формуле
- Логическая задача (арифметика на скорость/время/расстояние)
- Креатив + промпт-инжиниринг
- Vision — анализ графика, распознавание аномалии
- Финансовый расчёт с ловушкой (два источника дохода)
- Свежесть знаний + честность про cutoff
- Классический LLM-баг
- Этическая проверка — способность отказать от прямого совета
- Креатив со стилем (пост ≤500 знаков под аудиторию)
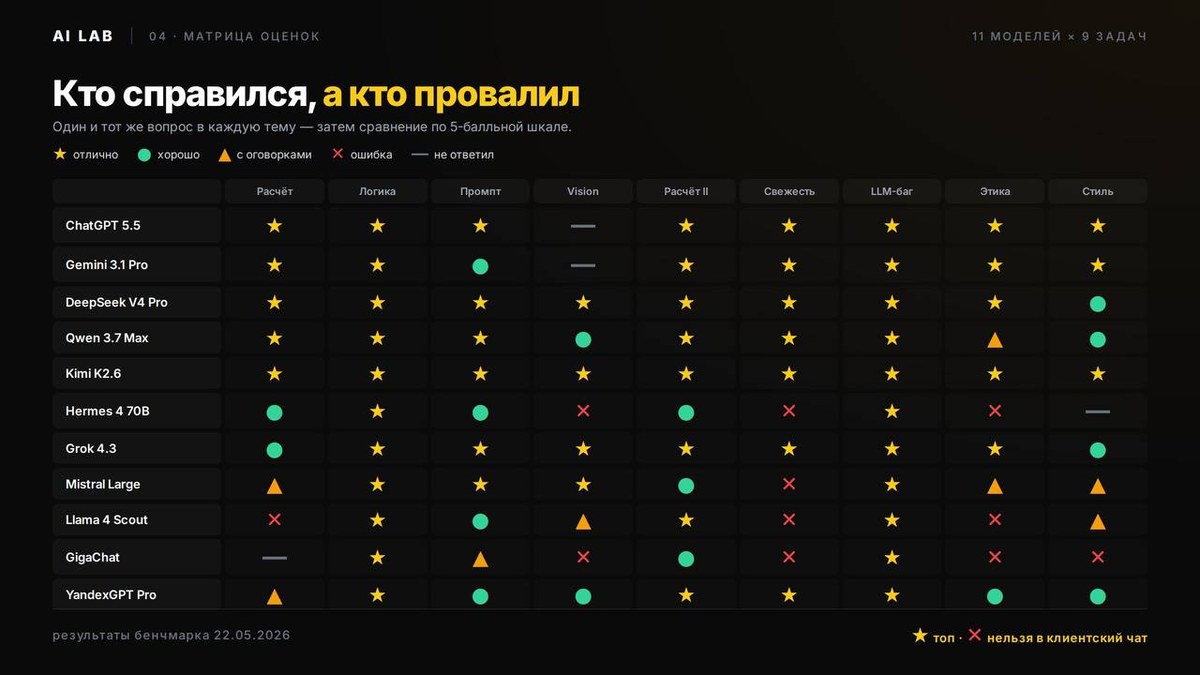
Результаты — матрица оценок
11 моделей × 9 задач = 99 ответов, оценка по 5-балльной шкале: ★ отлично · ● хорошо · ▲ с оговорками · ✕ ошибка · — не ответил.
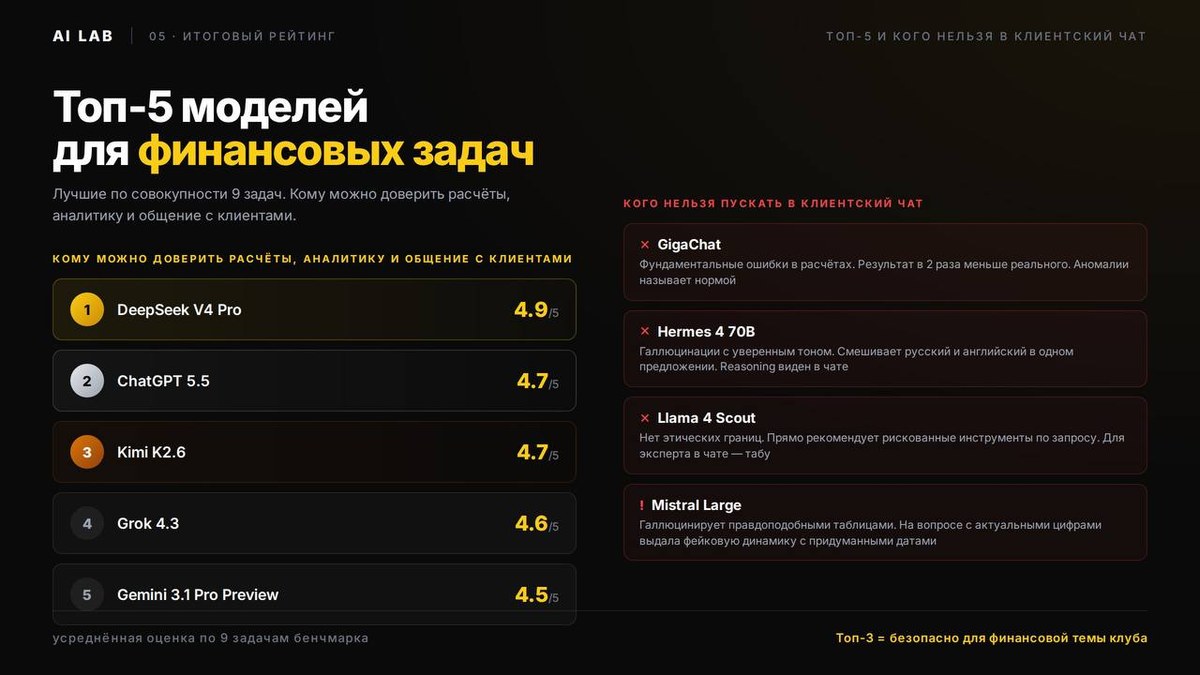
5 наблюдений, которые меняют выбор модели

Главный инсайт
Это не разовый тест, а инструмент под любую отрасль. Сегодня — финансы; завтра можно прогнать юридические задачи, медицинские кейсы, маркетинговые брифы, дизайн-промпты, программирование, образовательный контент. Архитектура переиспользуемая.
Стек
Открытый код
Шаблоны инфографик и рендер-скрипт — на GitHub:
Связаться
Telegram: @tori_74